Komponenten der Veröffentlichung
In diesem Thema
Komponenten der Veröffentlichung
Der primäre Datenspeicher für katalogisierte Metadatendokumente ist ein relationales Datenbankmanagementsystem. Eine Liste unterstützter Datenbanksysteme finden Sie im Geoportal-Thema Vorinstallation. Die relationale Datenbank enthält Tabellen, die mit dem Genehmigungsstatus der Ressource, der Veröffentlichungsmethode und weiteren Identifikationsattributen verknüpft sind. Sie enthält auch Tabellen für referenzierte Benutzer (Benutzer mit Daten innerhalb des Katalogs), für die Synchronisierung registrierte Remote-Repositories und gespeicherte Suchvorgänge pro Benutzer. Das Geoportal verwendet bei der direkten Kommunikation mit der relationalen Datenbank die Standard-JDBC-API (Java Database Connectivity). Die primären Komponenten, die mit der Veröffentlichung von Dokumenten im Geoportal-Metadatenkatalog zusammenhängen, werden in der folgenden Abbildung dargestellt.
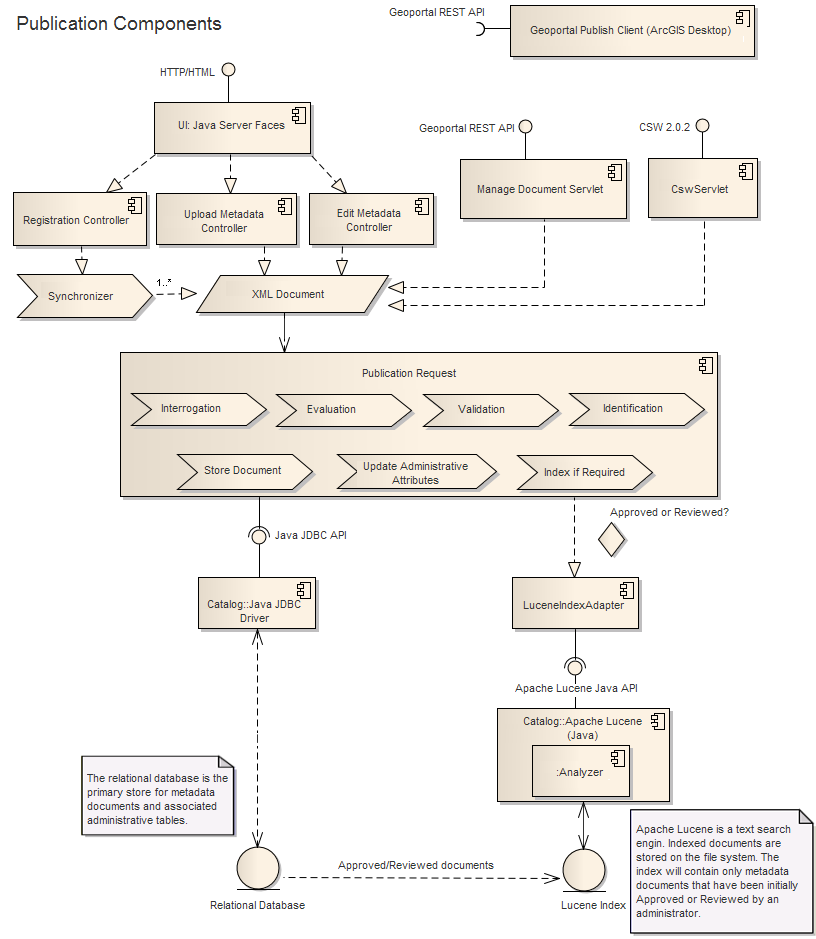
Metadatendokumente, die von einem Administrator entweder als "Genehmigt" oder "Überprüft" klassifiziert wurden, werden an den vom Geoportal verwendeten Apache Lucene Index gesendet. Im Index gespeicherte Dokumente können über eine Suche gefunden werden. Apache Lucene implementiert während der Indizierung (und Suche) eine Analysefunktion. Die Aufgabe einer Analysefunktion besteht darin, Begriffe mit einem Token zu versehen und dabei sprachbasierte Stoppwörter und Wortstämme zu berücksichtigen. Zusätzliche Analysefunktionen sind bei der Apache Lucene-Community verfügbar, die hierzu regelmäßig Beiträge leistet. Die Website hat zwei Seiten, die Endpunkte für die Veröffentlichung von Metadaten bereitstellt:
- Die Seite "Hochladen", über die Publisher Metadatendokumente von einer Festplatte oder einem HTTP-Endpunkt hochladen können.
- Eine Online-Editor-Seite, über die Publisher Metadatendokumente erstellen und bearbeiten können. Nur Dokumente, die mit dem Online-Editor erstellt wurden, können später bearbeitet werden.
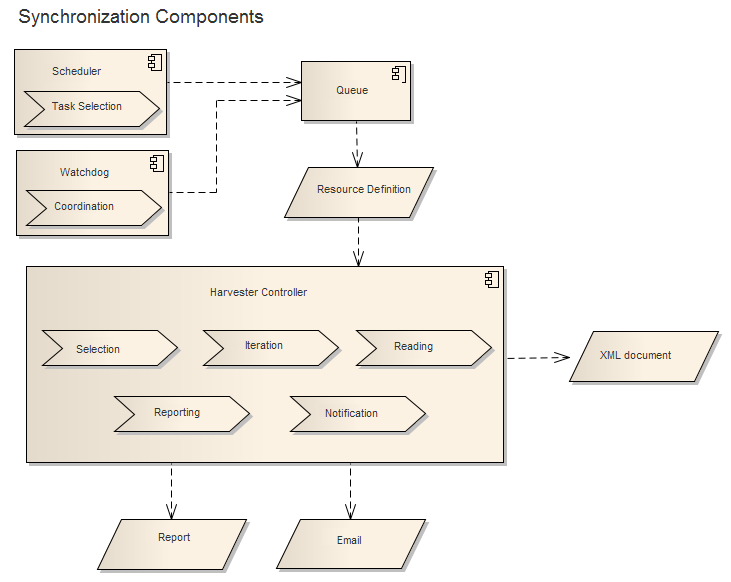
Innerhalb des Synchronisierungsprozesses reiht der Planer registrierte Ressourcen für die Synchronisierung in die Warteschlange ein. Der Watchdog wird nur in einer Lastenausgleichsumgebung verwendet, um koordinierte Synchronisierungsprozesse zu gewährleisten. Sobald die Warteschlange Ressourceninformationen empfängt, ruft sie über das Ressourcendefinitionselement Verbindungsinformationen zur Ressource auf und fährt mit der Synchronisierung im dedizierten Thread fort. Die Ressourcendokumente werden entweder aus dem Zielkatalog ausgewählt oder auf Basis der verfügbaren Ressourceninformationen erstellt. Die Ausgabe des Auswahl-, Iterations- und Leseprozesses bildet ein XML-Dokument, das durch die unten beschriebene Komponente für die Veröffentlichungsanforderung gesendet wird. Der dedizierte Thread für die Synchronisierung erstellt außerdem einen Bericht, der über die Geoportal-Benutzeroberfläche auf der Seite Synchronisierungsbericht der Ressource angezeigt wird. Auf der Seite für das Erstellen oder Bearbeiten von Ressourcen können Sie festlegen, dass Ihnen eine E-Mail mit den Synchronisierungsergebnissen gesendet wird.
Auf der Website wird auch eine REST-API angezeigt, sodass eine kompatible Veröffentlichung von Metadatendokumenten aus Client-Anwendungen wie ArcCatalog möglich ist. Der Geoportal Publish Client ist ein Plug-In für ArcCatalog, das über diesen Endpunkt Metadatendokumente (aus Ordnern oder Geodatabases) als Batches veröffentlicht.
Mit jeder Veröffentlichungsanforderung wird für die Verarbeitung eines XML-Metadatendokuments eine Standardmethodik implementiert:
- Untersuchung: Das Dokument wird untersucht, um den damit verknüpften Metadatenstandard zu bestimmen.
- Überprüfung: Das Dokument wird gemäß der Konfigurationsdatei überprüft, die mit dem Standard verknüpft ist. Bei der Überprüfung werden die primären Parameter ermittelt, die von Interesse sind (z. B. Bezeichnung, Überblick, …).
- Validierung: Das Dokument wird gemäß der Konfigurationsdatei validiert, die mit dem Standard verknüpft ist. Wenn der Standard über eine verknüpfte XSD (XML Schema Definition) verfügt, wird das Dokument mithilfe der XSD validiert.
- Identifikation: Es wird bestimmt, ob das Dokument derzeit im Katalog vorhanden ist. Dieser Schritt ist zur Vermeidung von Duplikaten notwendig und vom Inhalt des Dokuments (einige verfügen über interne Kennungen) und der Veröffentlichungsmethode (einige Methoden können eine eindeutige URI zur Verfügung stellen, die mit der Quelle verknüpft ist) abhängig.
- Speichern des Dokuments: Das Dokument wird zum Speichern an die relationale Datenbank gesendet.
- Aktualisieren von Administratorattributen: Administratorattribute innerhalb der relationalen Datenbank werden über die JDBC-API aktualisiert. Folgendes ist enthalten: die Veröffentlichungsmethode, eine interne Dateikennung, falls verfügbar, eine mit der Quelle verknüpfte URI, falls verfügbar.
- Index, falls erforderlich: Wenn das Dokument zuvor von einem Administrator genehmigt oder überprüft wurde (oder wenn es genehmigt oder überprüft wird), wird es an den Apache Lucene-Index gesendet. Bei diesem Schritt wird eine Geoportal-Klasse verwendet (LuceneIndexAdapter), um mit dem Index über die Apache Lucene Java-API zu kommunizieren.