Componentes de la publicación
El almacén de datos principal para los documentos de metadatos catalogados es un sistema de administración de bases de datos relacionales. Consulte el tema Preinstalación del geoportal para ver una lista de los sistemas de bases de datos admitidos. La base de datos relacional contiene tablas relacionadas con el estado de aprobación de los recursos, el método de publicación y otros atributos de identificación. También incluye tablas para usuarios a los que se hace referencia (usuarios que poseen datos dentro del catálogo), repositorios remotos registrados para la sincronización y búsquedas grabadas por el usuario. El Geoportal usará el API JDBC de Java estándar cuando se comunique directamente con la base de datos relacional. Los componentes principales asociados con la publicación de los documentos en el catálogo de metadatos del Geoportal se muestran en la figura a continuación.
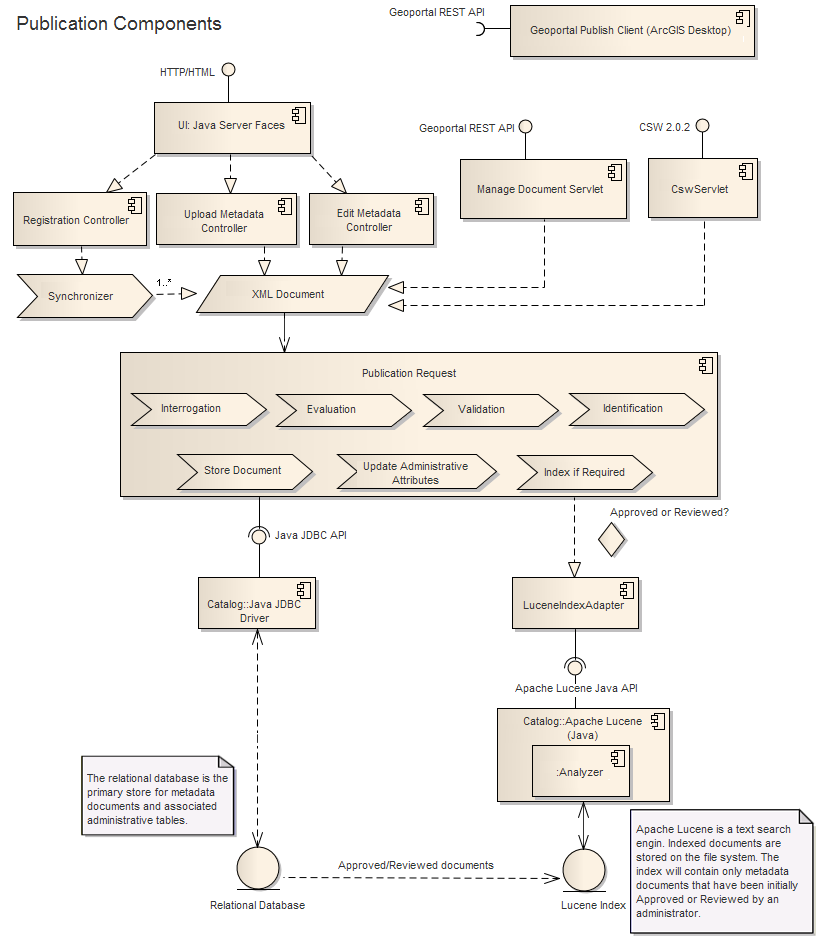
Los documentos de metadatos que un administrador clasifique como "Aprobados" o "Revisados" se envían al índice de Lucene de Apache que usa el Geoportal. Los documentos almacenados dentro del índice se pueden descubrir a través de la búsqueda. Apache Lucene implementa un Analizador durante el proceso de indexación (y búsqueda). El trabajo del Analizador es acortar términos, considerando el lenguaje con base en palabras irrelevantes y lematización. Los Analizadores adicionales están disponibles a través de la comunidad de contribución Apache Lucene. El sitio Web tiene dos páginas que exponen los puntos finales de la publicación de metadatos:
- Una página para cargar que le brinda a un publicador la capacidad de cargar documentos de metadatos desde un disco duro o desde un punto final HTTP
- Una página de edición en línea que le brinda a un publicador la capacidad de crear y editar documentos de metadatos. Únicamente estos documentos que han sido creados por el editor en línea están disponibles para una edición posterior.
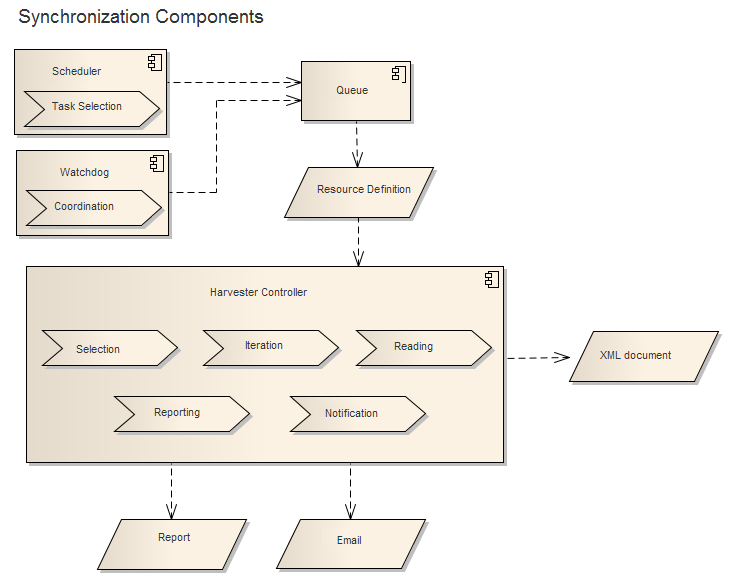
Dentro del proceso de sincronización el programador asigna los recursos registrados a la cola para la sincronización. El watchdog se utiliza únicamente en un entorno de equilibrio de carga para garantizar que los procesos de sincronización estén coordinados. Una vez que la cola recibe información del recurso, ésta adquiere la información de la conexión del recurso a través del elemento de definición de recursos y procede por medio de un subproceso de sincronización dedicado. Los documentos de recursos se seleccionan del catálogo objetivo o se crea con base en la información de recursos disponible. La salida de la selección, la iteración y el proceso de lectura es un documento xml que se enviará a través del componente de solicitud de publicación que se describe a continuación. En el subproceso de sincronización dedicado también se crea un informe que se puede ver en la interfaz de usuario del Geoportal, en la página Informe de sincronización del recurso. Como una opción en la página Crear o Editar recursos puede elegir recibir un correo electrónico de los resultados enviados de la sincronización.
El sitio Web también expone un API REST, lo que permite la publicación compatible de los documentos de metadatos desde las aplicaciones del cliente como ArcCatalog. El Cliente de publicación del Geoportal es un complemento de ArcCatalog que permite publicar los documentos de metadatos en lote (ya sea de carpetas o de GeoDatabases) a través de este extremo.
Cada solicitud de publicación implementa una metodología estandarizada para procesar un documento de metadatos XML:
- Consulta: el documento se consulta para ver el estándar de metadatos que tiene asociado.
- Evaluación: el documento se evalúa con respecto al archivo de configuración asociado al estándar. La evaluación determina los parámetros principales de interés (como el título, abstracción, …)
- Validación: el documento se valida con respecto al archivo de configuración asociado al estándar. Si el estándar tiene un XSD asociado (Definición del esquema XML), se validará el documento contra el XSD.
- Identificación: se averigua si el documento existe actualmente o no en el catálogo. Este paso es necesario para evitar la duplicación y depende del contenido del documento (algunos tienen identificadores internos) y del método de publicación (algunos métodos pueden proporcionar un URI único asociado con el origen).
- Almacenar el documento: el documento se envía a la base de datos relacional para almacenarlo.
- Actualizar los atributos administrativos: se actualizan los atributos administrativos de la base de datos relacional mediante el API Java JDBC. Esto incluye: el método de publicación, un identificador interno del archivo (si está disponible) y un URI asociado al origen, si está disponible.
- Indexar si es necesario: si un administrador ha aprobado o revisado previamente el documento (o cuando se apruebe o se revise), se envía al índice de Lucene de Apache. Este paso usa una clase del Geoportal (LuceneIndexAdapter) para comunicarse con el índice a través del API de Java de Apache Lucene.