Composants de publication
Le stockage de données principal pour les documents de métadonnées catalogués est un système de gestion de base de données relationnelles. Voir la rubrique Préinstallation du géoportail pour obtenir une liste des systèmes de base de données pris en charge. La base de données relationnelles contient des tables associées à l'état d'approbation de la ressource, à la méthode de publication et aux attributs d'identification supplémentaires. Elle contient également des tables pour les utilisateurs référencés (les utilisateurs possédant des données dans le catalogue), les répertoires enregistrés pour synchronisation et les recherches enregistrées par utilisateur. Le Géoportail utilisera l'API JDBC Java standard pour communiquer directement avec la base de données relationnelles. Les principaux composants associés à la publication de documents vers le catalogue de métadonnées du Géoportail sont représentés dans la figure ci-dessous.
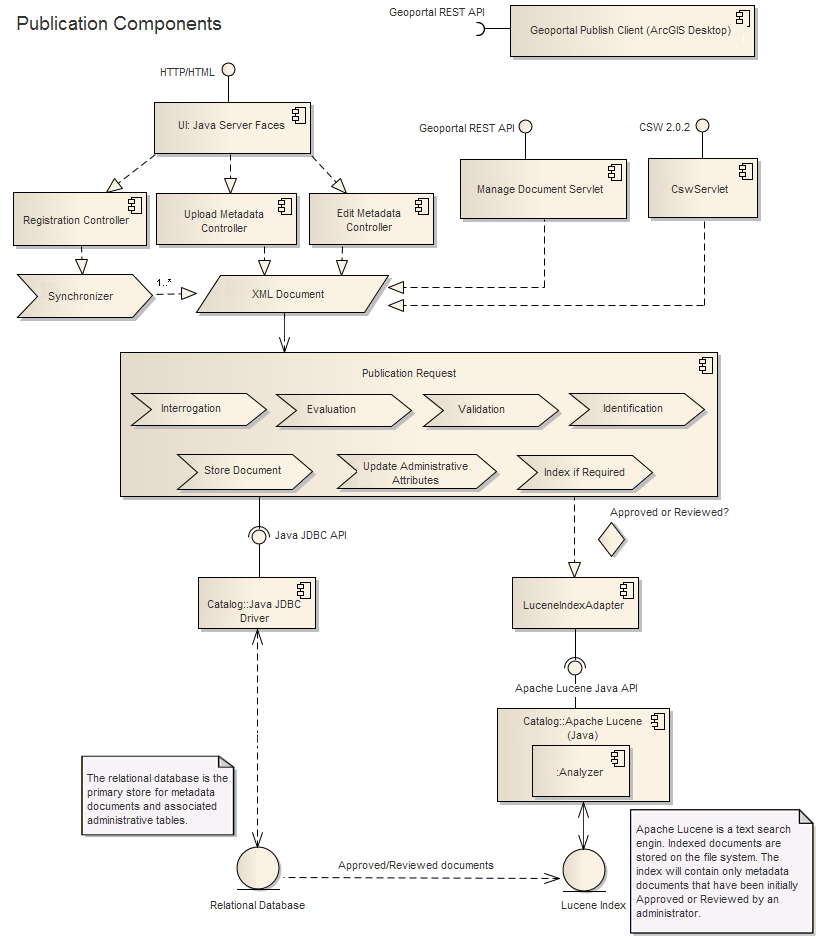
Les documents de métadonnées qui sont classés comme "Approuvé" ou "Révisé" par un administrateur seront envoyés à l'index Apache Lucene utilisé par le Géoportail. Les documents stockés dans l'index sont découvrables via la recherche. Apache Lucene implémente un Analyseur lors du processus d'indexation (et de recherche). La mission de l'Analyseur consiste à marquer les termes, en prenant en compte les mots vides et la racinisation de la langue. D'autres Analyseurs sont disponibles dans la communauté de contribution d'Apache Lucene. Le site Web a deux pages exposant les extrémités de publication des métadonnées :
- Une page de téléchargement qui permet à un éditeur de télécharger les documents de métadonnées à partir d'un disque dur ou d'une extrémité HTTP
- Une page d'éditeur en ligne qui permet à un éditeur de créer et de modifier les documents de métadonnées. Seuls ces documents qui ont été créés par l'éditeur en ligne peuvent être modifiés ultérieurement.
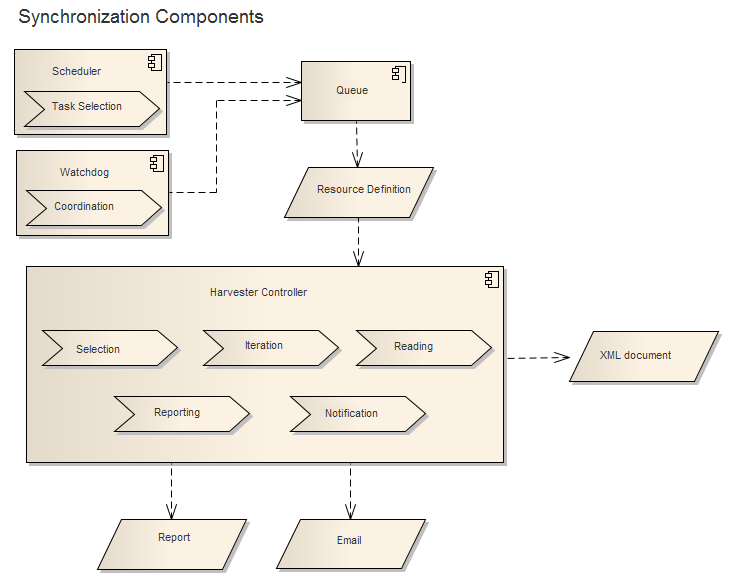
Dans le processus de synchronisation, le planificateur attribue les ressources enregistrées à la file d'attente pour synchronisation. L'horloge de surveillance est utilisée uniquement dans un environnement de charge équilibrée afin d'assurer que les processus de synchronisation sont coordonnés. Une fois que la file d'attente reçoit les informations de ressources, elle acquiert les informations de connexion par le biais de l'élément de définition de ressources et continue par le biais du thread de synchronisation dédié. Les documents de ressources sont sélectionnés à partir du catalogue cible ou créés en se basant sur les informations de ressources disponibles. La sortie du processus de sélection, d'itération et de lecture est un document xml qui sera envoyé via le composant de requête de publication décrit ci-dessous. Le thread de synchronisation dédié créé également un rapport qui est visible par l'intermédiaire de l'interface utilisateur du géoportail sur la page Rapport de synchronisation de la ressource. Comme option sur la page Créer ou modifier la ressource, vous pouvez choisir d'avoir un e-mail des résultats de synchronisation envoyés.
Le site Web expose également un API REST, permettant une publication compatible des documents de métadonnées à partir des applications clients telles qu'ArcCatalog. Le Client de publication du Géoportail est un plug-in pour ArcCatalog. Ce lot publie les documents de métadonnées (à partir de dossiers ou de GéoDatabases) par le biais de cette extrémité.
Chaque requête de publication implémente une méthodologie normalisée pour traiter un document de métadonnées XML :
- Interrogation : le document sera interrogé pour déterminer sa norme de métadonnées associée
- Évaluation : le document sera évalué selon le fichier de configuration associé à la norme. L'évaluation détermine les principaux paramètres d'intérêt (comme le titre, le résumé, …)
- Validation : le document sera validé selon le fichier de configuration associé à la norme. Si la norme a un XSD associé (XML Schema Definition), le document sera validé par rapport au XSD.
- Identification : une détermination est faite quant à si le document existe actuellement ou non dans le catalogue. Cette étape est nécessaire pour éviter la duplication et dépend du contenu du document (certains ont des identifiants internes) et de la méthode de publication (certaines méthodes peuvent fournir un URI unique associé à la source).
- Stockage du document : le document est envoyé à la base de données relationnelles pour stockage.
- Mise à jour des attributs administratifs : les attributs administratifs dans la base de données relationnelles sont mis à jour via l'API JDBC Java. Sont inclus : la méthode de publication, l'identifiant interne d'un fichier si disponible, un URI associé à la source si disponible.
- Index si requis : si le document a été précédemment Approuvé ou Révisé par un administrateur (ou lorsqu'il est Approuvé ou Révisé), il est envoyé à l'Index d'Apache Lucene. Cette étape utilise une classe du Géoportail (LuceneIndexAdapter) pour communiquer avec l'index via l'API Java d'Apache Lucene.
Vous avez un commentaire à formuler concernant cette rubrique ?